들어가기 앞서
이 글은 이전 글에서 이어지는 글로 코드적으로 알림 중복 전송 처리를 고도화하기 위해 고민했던 내용이 담긴 글입니다.
이해를 위해 이전 글을 먼저 일고 오시면 흐름을 이해하는데 도움이 될 것입니다.
2025.04.12 - [분류 전체보기] - 분산 서버에서 푸시 알림 중복 전송 문제 해결기 1편
동적 TTL 설정
이전에 레디스의 락 만료 시간이 고정되어 있다는 문제점이 있어서 이를 동적 TTL 설정하는 방식으로 해결한다고 했었습니다.
실제로 어떻게 구현했는지에 대해서 살펴보겠습니다.
락을 획득한 경우, 작업이 진행되는 동안에는 락의 만료 시간이 계속해서 연장되어야 합니다. 이를 위해선 “작업이 끝났는지”를 확인하는 작업이 필요합니다. 그리고 이 확인하는 작업을 크게 2가지 방식으로 설정할 수 있었습니다.
1. 데몬 쓰레드 기반
2. 코루틴 기반
각각의 방식에 대해서 자세히 살펴보겠습니다.
데몬 쓰레드 기반 Watchdog
fun processWithLock(
lockKey: String,
action: () -> Boolean
): Boolean {
(... 락 획득 시도)
if (락 획득 실패) {
return false
}
// ⭐️ Whatchdog 부분
val watchdogThread = thread(start = true, isDaemon = true) {
while (keepExtending) {
Thread.sleep(500)
val ttlMillis = ttl.toMillis().toString()
val lockExtendResult = lockRedisTemplate.execute(
lockExtendScript,
listOf(lockKey),
lockValue,
ttlMillis
)
if (lockExtendResult == 1L) {
log.info { "\uD83C\uDF00 $lockKey Lock extended by ${ttlMillis}ms." }
continue
}
log.warn { "❌$lockKey Failed to extend lock" }
keepExtending = false
}
}
(... 락 반환 로직)
return result
}위 방식은 데몬 쓰레드를 만들어서 작업이 끝났는지 일정 기간마다 확인하는 코드입니다.
위 코드를 실제로 테스트를 돌려보면 아래와 같이 나옵니다.

thraed-230은 작업 쓰레드로 락을 획득하고 작업을 진행하고 작업이 완료되면 락을 반환합니다.
Thead-4 는 데몬 쓰레드로 작업이 끝났는지 감시하면서 아직 끝나지 않은 경우 락을 자동으로 연장합니다.
데몬 쓰레드
그렇다면 데몬 쓰레드가 무엇일까요??
데몬 쓰레드(Daemon Thread)는 JVM 종료 시 생존 여부에 영향을 주지 않는 백그라운드용 쓰레드이다.
|
일반 쓰레드
|
데몬 쓰레드
|
|
종료되지 않으면 JVM도 종료 안 됨
|
모든 일반 스레드가 끝나면 JVM은 데몬도 강제 종료함
|
|
예: main thread, worker thread
|
예: GC, 모니터링, 백그라운드 반복 작업 등
|
Watchdog thread는 백그라운드에서 작업이 끝났는지에 대해서 지속적으로 반복하는 작업이기에 데몬 쓰레드로 구현하는것이 적절합니다. 만약 일반 쓰레드로 만들게 되면, 쓰레드가 살아 있으면 JVM 프로세스가 종료되지 않게 되면서 문제가 발생할 수 있습니다. 작업이 끝났는지 확인하는 작업은 서비스의 핵심 흐름이 아니기 때문에 JVM 프로세스가 종료될 때 자동으로 같이 종료되게 데몬 쓰레드를 사용하는 것이 적절합니다.
단점
데몬 쓰레드로 Watchdog을 구현하게 되면 매번 요청마다 쓰레드를 생성하게 된다는 치명적인 단점이 있습니다. 요청이 많아질 경우, 쓰레드 수가 급격히 늘어나게 되면서 JVM 리소스를 과하게 점유할 위험이 있습니다.
그렇다면 쓰레드 풀을 사용하면 안되나 의문이 들 수 있습니다. 저도 그렇게 생각했었데 살펴보니 쓰레드 풀을 사용하게 되면 감시 작업의 특성과 쓰레드 풀의 동작 방식 간의 충돌이 있을 수 있다고 합니다. 쓰레드 풀은 단발성 작업 처리용입니다. 그렇기에 작업 큐에 있는 짧은 작업을 빠르게 처리하기 위해 주로 사용하게 됩니다. 반면 Watchdog 같은 감시 작업은 단발성이 아니고 계속 진행되어야 하는 작업으로 쓰레드를 지속해서 점유하게 된다. 결국 쓰데르 풀의 크기가 제한되어 있으면 작업이 밀리거나 대기하게 되며 설정에 따라 쓰레드를 새롭게 생성하는 등의 작업이 일어날 수 있게 됩니다. 다시 말해서 쓰레드 풀을 사용하는 장점을 활용할 수 없게 되는 것입니다. 그냥 직접 쓰레드를 만드는 것과 다를 바 없어지는 것이죠. 쓰레드 풀의 장점을 활용할 수 없다면 쓰레드 풀을 활용하는 것은 결국 복잡성만 증가만 야기하게 됩니다.
코루틴은 어떨까?
데몬 쓰레드를 사용하게 되면 매번 요청할 때 마다 쓰레드가 생성된다는 단점이 있었습니다.
그렇다면 이를 해결하기 위해 데몬 쓰레드 대신 코루틴을 활용하면 어떨까요?
(코루틴에 대한 자세한 설명은 제가 예전에 쓴 글을 참고하면 좋을 것 같습니다)
간단하게 말하면 코루틴을 활용하게 되면 경량 쓰레드를 사용하여 매번 쓰레드를 생성하는 방식이 아닌 쓰레드 풀 위에서 경량 쓰레드처럼 동작하게 됩니다.
그렇다면 실제로 얼마만큼의 성능 차이가 있을까요?
궁금해서 저는 직접 테스트를 진행해 보았습니다.
아래 테스트는 약 100개의 작업을 동시 요청했을 때의 리소스 차이를 그래프로 그린 것입니다.
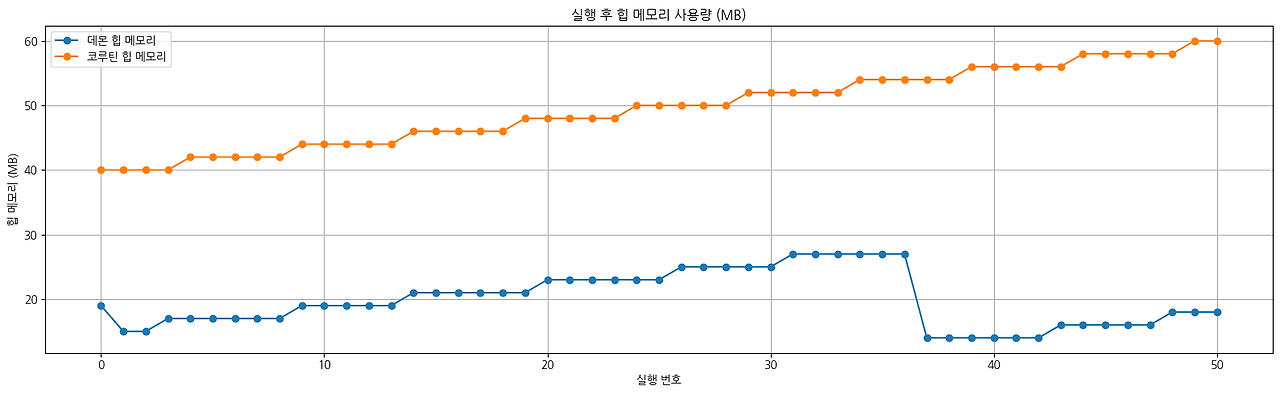
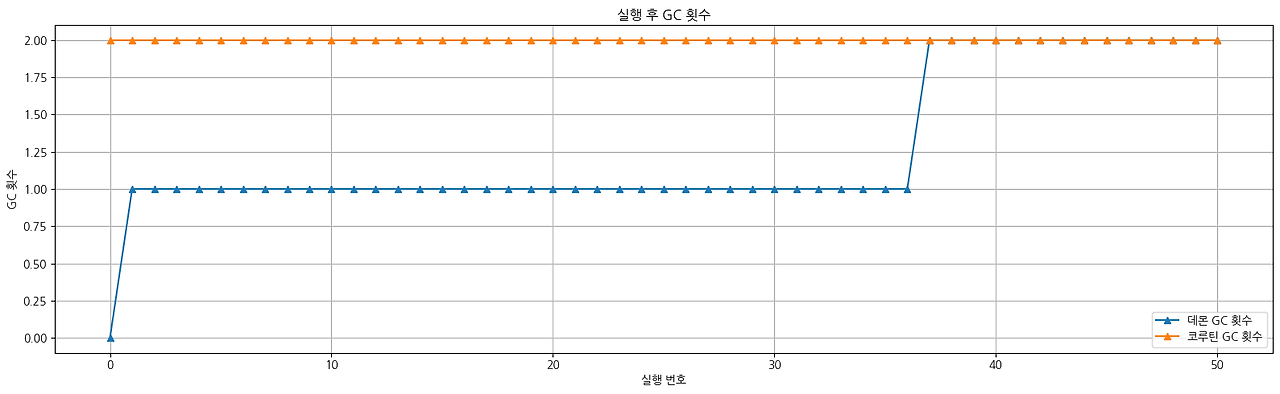
위 표를 살펴보면 주황색은 코루틴이고 파란색은 데몬 쓰레드 방식입니다.
둘을 비교해 보면 예상외로 실행 시 사용하는 힙 메모리와 GC 횟수 모두 코루틴이 더 높았습니다.
코루틴은 실행 시마다 컨텍스트 객체, Job 객체 등을 할당하여 힙에 보관하게 되는데 이러한 구조적 특성상 100개의 코루틴을 띄우면 관련 부가 데이터가 함께 생성됩니다. 따라서 힙 메모리 사용량이 증가하고 GC 입장에는 더 많은 객체를 관리해야 하므로 GC 횟수도 증가하는 것입니다.
그렇다면 데몬 쓰레드를 사용하는 방식이 코루틴을 활용하는 것보다 더 적은 리소스를 사용하는 것일까요?
결론부터 말하면 코루틴을 활용하는 것이 리소스가 더 적게 소모합니다.
아래는 100번의 요청을 동시에 보내 데몬 쓰레드와 코루틴의 쓰레드 사용량을 그래프로 그린 것입니다.
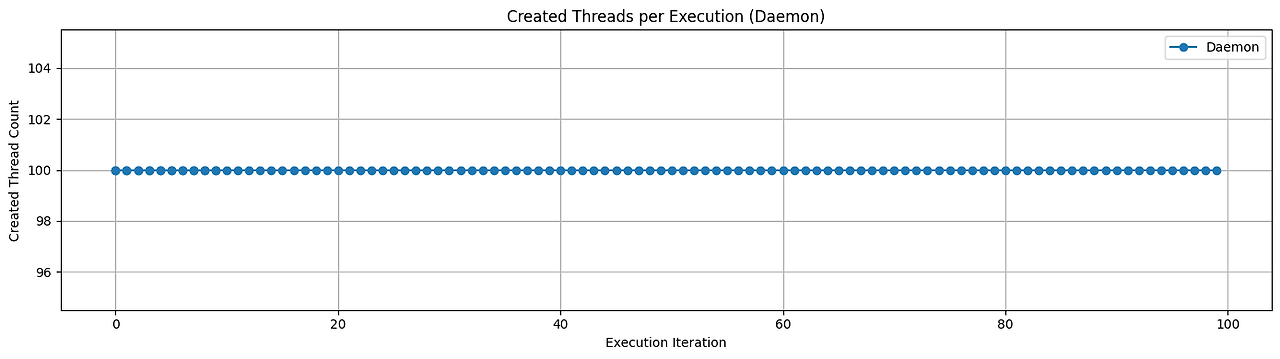
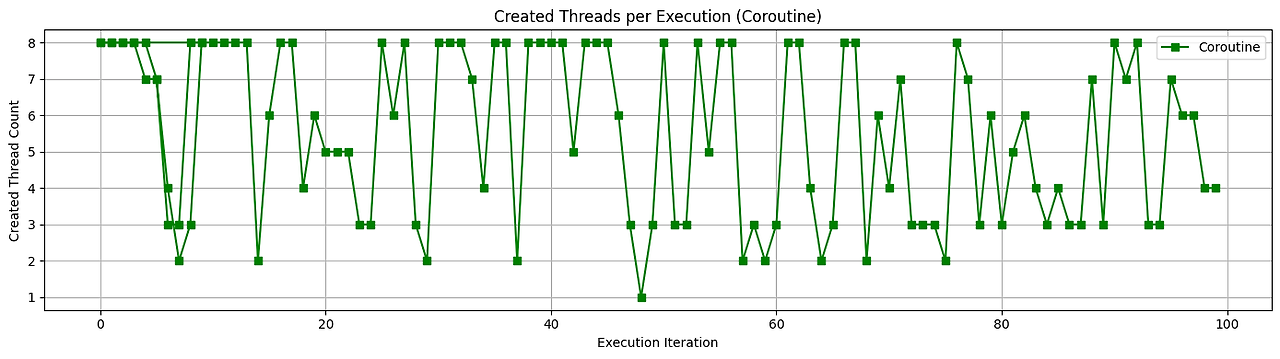
테스트 결과, 데몬 쓰레드 방식은 매 작업마다 새로운 쓰레드를 생성하기 때문에 약 100개의 고유 쓰레드가 생성되었습니다.
반면, 코루틴 기반 방식은 동일한 100개의 작업을 처리하면서도 평균 3~8개의 스레드만으로 충분히 처리되었죠. 코루틴이 스레드를 점유하지 않고 비동기적으로 동작한다는 구조적 장점 덕분입니다.
“쓰레스 수”는 GC나 메모리 사용량보다 시스템 한계에 훨씬 더 직접적인 영향을 끼칩니다. 쓰레드는 생각보다 무거운 리소스 단위입니다. 쓰레드 하나는 컨텍스 전환이 필요한 작업 단위죠. 따라서 100개의 쓰레드를 동시에 띄우게 되면 그 만큼 스케줄링, 컨텍스트 전환 비용, 메모리, 커널 리소스가 전부 발생하게 됩니다.
따라서 GC 횟수나 힙 메모리 사용량이 일시적으로 더 높을 수 있지만, 쓰레드 사용 수가 적은 코루틴이 전체 시스템 리소스 효율성과 확장성 관점에서 더 적절한 선택이라고 봅니다.
코루틴 방식으로 리팩터링
그렇다면 기존의 데몬 쓰레드 방식의 Watchdog을 코루틴 방식으로 변경해 보겠습니다.
private const val SUCCESS = 1L
private const val BUFF_RATIO = 1.5
private const val WATCHDOG_SLEEP_RATIO = 2
fun processWithLock(
lockKey: String,
action: () -> Boolean
): Boolean {
(... 락 획득 시도)
if (락 획득 실패) {
return false
}
// ⭐️ Whatchdog 부분
var watchdogJob =
CoroutineScope(Dispatchers.Default).launch {
val sleepMills = expectedActionDurationMillis / WATCHDOG_SLEEP_RATIO
while (true) {
Thread.sleep(sleepMills)
val lockRefreshResult =
lockRedisTemplate.execute(
lockRefreshScript,
listOf(lockKey),
lockValue,
(expectedActionDurationMillis * BUFF_RATIO).toLong().toString()
)
if (락 연장에 성공하면) {
log.info { "\uD83C\uDF00 $lockKey Lock extended by ${expectedActionDurationMillis}ms." }
} else {
log.warn { "❌$lockKey Failed to extend lock" }
}
}
}
var result = false
runBlocking {
try {
result = action()
} finally {
watchdogJob.cancel()
(... 락 반환 로직)
}
}
return result
}변경된 코드는 위와 같습니다. 이제 Watchdog에서 쓰레드를 생성하는 것이 아닌 코루틴으로 동작하게 되는데 쓰레드 풀 위에서 경량 쓰레드가 Watchdog 작업을 수행하게 됩니다.
실제 위 로직을 실행하는 테스트를 보면 아래와 같이 로그가 나옵니다.
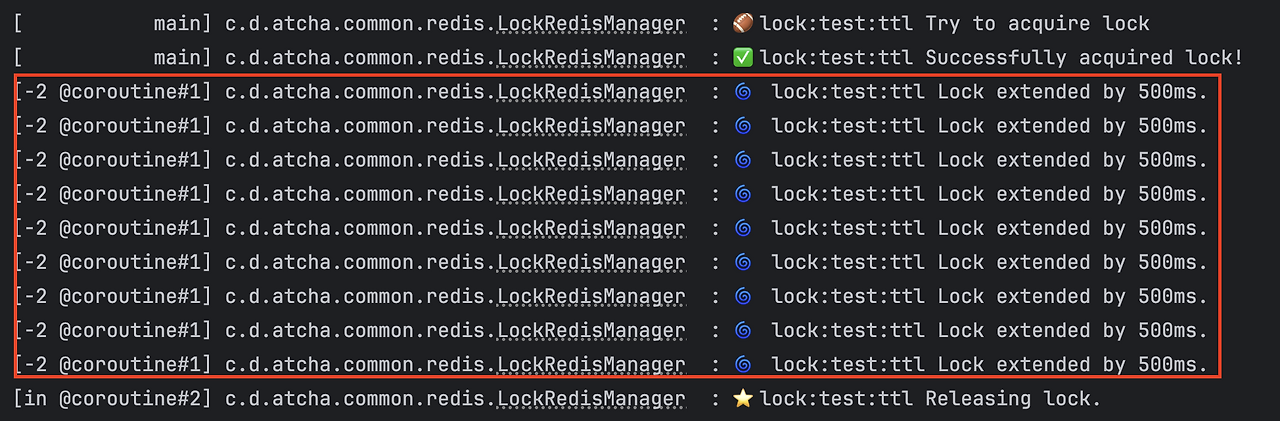
락을 획득하는 쓰레드와 락을 연장하는 쓰레드가 다른 것을 확인할 수 있죠. 여기서 락을 연장하는 쓰레드(-2 @courinte#1)는 실제 쓰레드가 아닌 경량 쓰레드로 OS 쓰레드가 아닌 비동기 작업 단위입니다. 따라서 훨씬 효율적으로 처리되죠.
참고) 락을 반환하는 쓰레드가 Main이 아닌 이유는 무엇일까요❓
runBlocking은 호출한 쓰레드에서 새로운 코루틴을 시작합니다. 그리고 해당 코루틴이 완료될 때 까지 그 쓰레드를 블로킹하도록 설계되어 있다. 그러나 runBlocking 내부에서 suspend 함수(delay, withContext 등)을 호출되거나 코루틴 스케줄러가 개입할 필요가 있다고 판단되는 경우, 다른 쓰레드에서 재개(resume)될 수 있다.
runBlocking의 공식 시그니처를 살펴보겠습니다.
public fun <T> runBlocking( context: CoroutineContext = EmptyCoroutineContext, block: suspend CoroutineScope.() -> T ): Tcontext를 따로 지정하지 않은 경우 기본적으로 EmptyCoroutineContext를 사용하는 것을 볼 수 있습니다. 이 경우 runBlocking은 현재 쓰레드에서 코루틴을 시작하며, Dispatcher를 명시하지 않았기 때문에 특정 쓰레드 풀을 사용하지 않죠.
하지만 만약 내부 로직에 따라 코루틴 스케줄러가 최적화를 위해 worker thread를 할당하여 실행할 수 있습니다.
실제로 아래와 같이 테스트해 본 결과 runBlocking 내부에서 다른 쓰레드를 사용하는 것을 볼 수 있었습니다.
@Test fun `runBlockingTest`() { log.info { "start" } // main val result = runBlocking { log.info { "inside block" } // coroutine } log.info { "end" } // main }
runBlocking의 본질은 “어디에서 실행되느냐”가 아니라 “무엇을 동기적으로 실행하느냐”입니다. runBlocking 내부 블록이 어디에서 실행되는지는 관심거리가 아닙니다. 단지 내부 블록이 모두 완료가 될 때까지 대기하고 이후 로직을 실행하는 것이죠. 다시 말해 동기적으로 실행하는 것입니다.
추가) 락 할당 시 Ratio 시간 부여
락을 재할당 하는 Watchdog가 있더라도 락을 얼마나 설정할지는 미리 정해야 했었습니다.
그리고 락을 연장하는 Watchdog도 얼마큼의 주기로 작업이 완료되었는지에 대해서도 결정했어야 했었습니다.
작업 예상 소요 시간(ETC)이 오래 걸리는 작업에 대해 너무 짧은 락 만료 시간을 할당하면 Watchdog 주기가 많아지게 되고 레디스 서버에 불필요한 부하를 줄 것입니다. 따라서 ETC에 따라 적절한 락 설정 시간과 Watchdog 주기가 달라지는 게 적절하다고 생각했습니다.
결론부터 말하자면 각 시간을 다음과 같이 설정했습니다.
- 락 만료 시간: 작업 예상 소요 시간(ETC) * 1.5
- Watchdog 주기: 작업 예상 소요 시간(ETC) / 2
작업에 대한 락을 부여할 때 작업 예상 시간의 + 버퍼 시간을 부여하여 락을 걸도록 변경하였습니다. 이때 비율을 1.5배로 설정하였습니다. 예상 작업 소요 시간이 10초인 경우 15초의 시간으로 락을 거는 것입니다.
락을 재할당 하는 시간도 ETC에 맞춰서 ETC / 2로 설정하였습니다. 구글링을 하다 보면 ETC / 10으로 설정하는 게 좋다는 의견도 있는데 현재 프로젝트에서는 아직 사용자가 많지 않기 때문에 “락으로 인한 유저 대기 시간”보다 “짧은 주기로 인한 레디스 서버 부담”이 더 비용이 크다고 느껴졌습니다. 따라서 더 긴 주기로 레디스에 요청을 하는 ETC / 2로 설정하였습니다.
마무리
전체적으로 지금까지의 내용을 정리해 보겠습니다.
분산 서버 환경에서 알림 중복 전송 문제가 발생했었고, 이를 해결하기 위한 첫 번째로 단일 서버에 배치하는 방식을 고려했습니다. 하지만 이 방식은 서버 가용성이 떨어지고 서버 환경이 일치하지 않는 문제가 있어 적절하지 않았죠. 이에 따라 분산 환경에서도 활용할 수 있는 레디스 분산락을 활용하는 방향으로 전환하였다. 이 과정에서 원자성이 보장되지 않고 TTL이 고정되어 있다는 문제점이 있었지만 Lua 스크립트를 활용하고 동적 TTL을 코루틴 기반의 Watchdog을 구현하여 해결하였습니다.
단순히 중복 전송 문제를 해결하려고 했지만 가용성과 효율성을 생각하다 보니 분산락, 코루틴 등의 깊은 개념도 배울 수 있었습니다. 아직은 개념이 확실히 잡혔다고는 느껴지지 않는다. 아직 익숙하지 않아서 그런 것 같습니다. 계속 고민해 보면서 해당 개념들을 체득해봐야 할 것 같습니다.
긴 글 읽어주셔서 감사합니다!